
Because I’ve used this code in many projects, I’ve decided to create a separate blog post detailing how I fetched songs.
I’ve created a Genius Parser, which accomplishes two things.
- Makes a http request to Genius to get url of song in search
- Web scrape the song url to get the lyrics of that song
This is a complex approach because Genius does not pass in song lyrics as part of the http request. Credit to Will Soares’s post for explaining this workaround.
I’ve then used this approach to accumulate a list of lyrics of #1 hip hop singles from 1980-present (around 400 songs).
HTTP Request
I’ve used Python’s request library to make a HTTP request to the Genius API. Below is the code.
def request_song_info(song_title, artist_name):
base_url = defaults['request']['base_url']
headers = {'Authorization': 'Bearer ' + defaults['request']['token']}
search_url = base_url + '/search'
data = {'q': song_title + ' ' + artist_name}
response = requests.get(search_url, data=data, headers=headers)
return response
Notice that I’m using a defaults object for getting base_url and headers. Below is the defaults object.
defaults = {
'request': {
'token': 'INSERT YOUR TOKEN HERE',
'base_url': 'https://api.genius.com'
}
}
You’ll notice that you need to put your own Genius API Token in INSERT YOUR TOKEN HERE. In order to use Genius APIs publically, you as a user have to provide an access token so Genius API can authenticate you as a user. And you have to put that access token as a Bearer token in all request headers so you can be authenticated to use the api (I did that for you in headers = {'Authorization': 'Bearer ' + defaults['request']['token']}).
So how do you get your access token? You need to sign up for an account on Genius. Then, you go to the documentation page to manage clients. Follow the steps to get your access token.
Web Scrape Genius Lyrics
Next step is to get the lyrics url. Below is a piece from my get_lyrics method. It’s pretty lengthy, so I included only bits that are needed for this post. I’ve listed my github code at the bottom of the post, so feel free to check it out.
def get_lyrics(songs_dict, decade_range):
#takes in a dictionary of all songs and the decade range they're part of.
#Below code is a segement of what I perform on each song in songs_dict.
...
response = request_song_info(song, artist)
json = response.json()
for hit in json['response']['hits']:
if artist.lower() in hit['result']['primary_artist']['name'].lower():
remote_song_info = hit
break
After getting remote_song_info, I want to get the song url
song_url = remote_song_info['result']['url']
Finally, I want to scrape the song url to get the lyrics of the song using this method below.
def scrap_song_url(url):
page = requests.get(url)
html = BeautifulSoup(page.text, 'html.parser')
[h.extract() for h in html('script')]
lyrics = html.find('div', class_='lyrics').get_text()
lyrics = re.sub('\[.*?\]', '', str(lyrics))
return lyrics
I’ve added a regex statement to exclude lines like [Verse 1: Drake] or [Verse 2: Chance the Rapper] from the lyrics.
Fetch Lyrics for 400 Hip Hop Singles
song_data_2010 = get_song_data('https://en.wikipedia.org/wiki/List_of_Billboard_Hot_Rap_Songs_number-one_songs_of_the_2010s')
song_data_2000 = get_song_data('https://en.wikipedia.org/wiki/List_of_Billboard_number-one_rap_singles_of_the_2000s')
song_data_1980 = get_song_data('https://en.wikipedia.org/wiki/List_of_Billboard_number-one_rap_singles_of_the_1980s_and_1990s')
get_song_data is my own web scraping method for Wikipedia. I’m not going to include the details here, so feel free to check my github code at the bottom of the post for more details.
song_data = [(song_data_2010, '2010-2020'),
(song_data_2000, '2000-2010'),
(song_data_1980, '1980-2000')]
pool = ThreadPool(3)
results = pool.starmap(get_lyrics, song_data)
pool.close()
pool.join()
lyrics_df = pd.DataFrame()
for result in results:
lyrics_df = lyrics_df.append(pd.DataFrame(result))
lyrics_df.to_csv('Rap_Lyrics_From_Different_Eras.csv')
I’m parsing around 200 songs from 1980-2000, 100 songs from 2000-2010m, and 80 songs from 2010-2020. I decided to run 3 different threads to parse each song decade group simultaneously. This saves a lot of time extracting lyrics from close to 400 songs. For more information on multithreaded web scraping, check this post here.
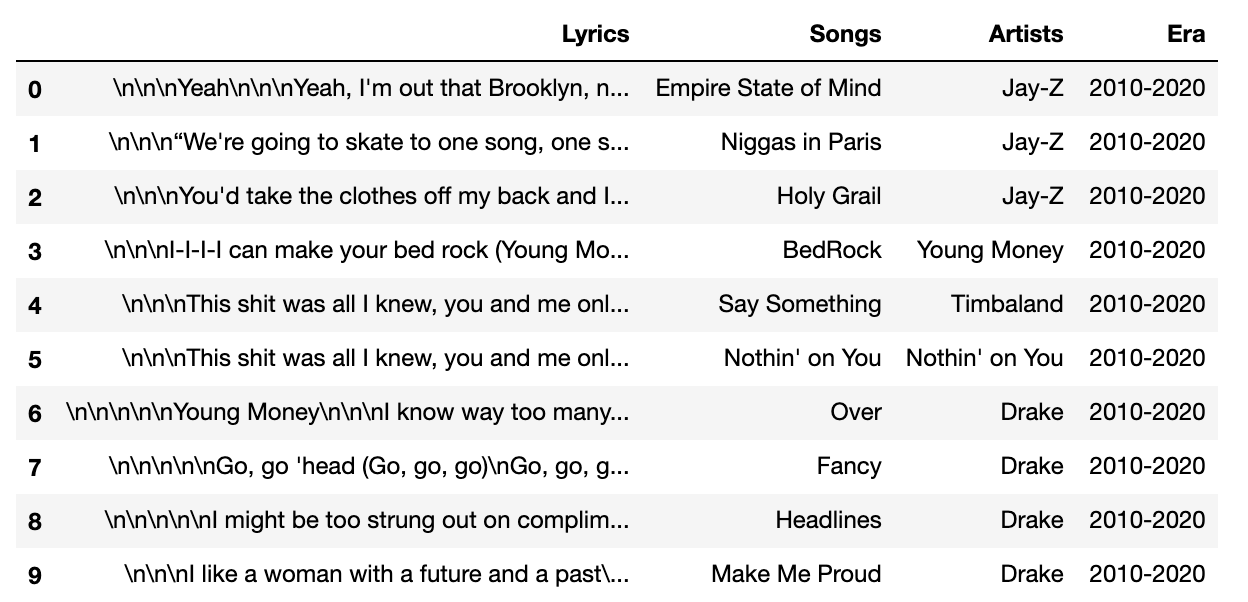
Below are some of the results in a dataframe.
For Github on all this code, see Genius parser.